任何构建工具的一个重要组成部分是避免重复已完成的工作。以编译过程为例。一旦源文件被编译,除非有影响输出的更改,例如修改源文件或删除输出文件,否则无需重新编译。编译可能需要大量时间,因此在不需要时跳过该步骤可以节省大量时间。
Gradle 通过一项名为增量构建的功能开箱即用地支持此行为。您几乎肯定已经看到它在运行中。当您运行一个任务并且该任务在控制台输出中标记为UP-TO-DATE时,这意味着增量构建正在工作。
增量构建是如何工作的?如何确保您的任务支持增量运行?让我们来看看。
任务输入和输出
在最常见的情况下,任务会获取一些输入并生成一些输出。我们可以将 Java 编译过程视为任务的示例。Java 源文件充当任务的输入,而生成的类文件,即编译结果,是任务的输出。
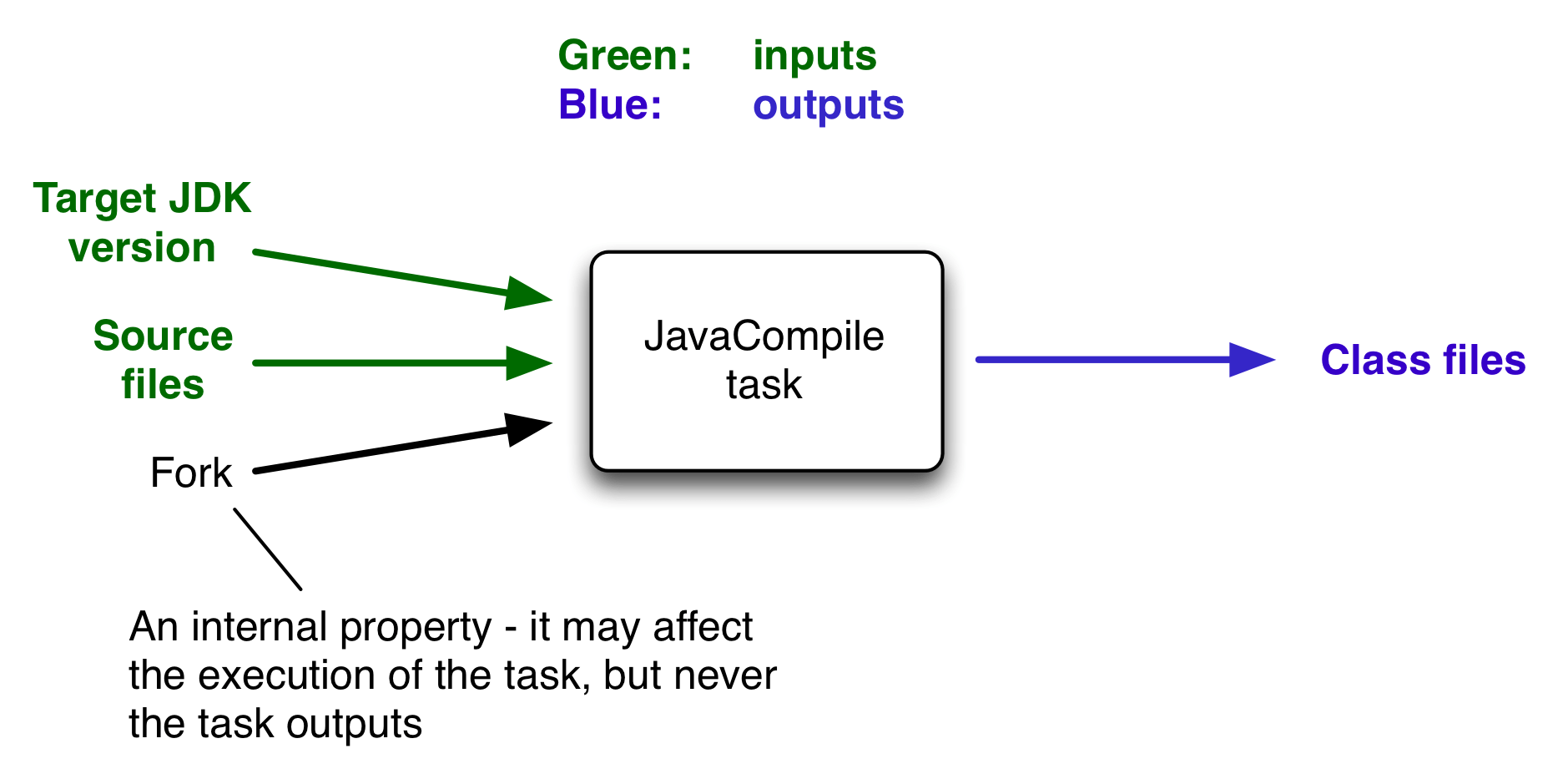
输入的一个重要特征是它会影响一个或多个输出,如您从上图中可以看到的。根据源文件的内容以及您想要运行代码的 Java 运行时的最低版本,会生成不同的字节码。这使得它们成为任务输入。但是编译是否有 500MB 或 600MB 的最大可用内存(由memoryMaximumSize属性确定)对生成什么字节码没有影响。在 Gradle 术语中,memoryMaximumSize只是一个内部任务属性。
作为增量构建的一部分,Gradle 会测试自上次构建以来是否有任何任务输入或输出发生了更改。如果它们没有更改,Gradle 可以认为任务是最新的,因此跳过执行其操作。另请注意,除非任务至少有一个任务输出,否则增量构建将无法工作,尽管任务通常也至少有一个输入。
这对构建作者来说意味着很简单:您需要告诉 Gradle 哪些任务属性是输入,哪些是输出。如果任务属性影响输出,请务必将其注册为输入,否则任务将在不是最新时被视为最新。相反,如果属性不影响输出,请不要将其注册为输入,否则任务可能会在不需要时执行。还要注意非确定性任务,它们可能为完全相同的输入生成不同的输出:这些任务不应配置为增量构建,因为最新检查将不起作用。
现在让我们看看如何将任务属性注册为输入和输出。
通过注解声明输入和输出
如果您正在实现一个自定义任务作为类,那么使其与增量构建一起工作只需两个步骤:
-
为每个任务输入和输出创建类型化属性(通过 getter 方法)
-
为每个属性添加适当的注解
| 注解必须放置在 getter 或 Groovy 属性上。放置在 setter 或没有相应注解 getter 的 Java 字段上的注解将被忽略。 |
Gradle 支持四种主要的输入和输出类别
-
简单值
例如字符串和数字。更一般地说,简单值可以具有实现
Serializable的任何类型。 -
文件系统类型
这些包括
RegularFile、Directory和标准File类,也包括 Gradle 的FileCollection类型的派生类以及任何可以传递给Project.file(java.lang.Object)方法(用于单个文件/目录属性)或Project.files(java.lang.Object...)方法的东西。 -
依赖解析结果
这包括用于 artifact 元数据的ResolvedArtifactResult类型和用于依赖图的ResolvedComponentResult类型。请注意,它们仅支持包装在
Provider中。 -
嵌套值
不符合其他两个类别但具有自己的输入或输出属性的自定义类型。实际上,任务输入或输出嵌套在这些自定义类型中。
例如,假设您有一个处理各种类型模板的任务,例如 FreeMarker、Velocity、Moustache 等。它获取模板源文件并将其与一些模型数据结合,以生成模板文件的填充版本。
此任务将有三个输入和一个输出
-
模板源文件
-
模型数据
-
模板引擎
-
输出文件的写入位置
当您编写自定义任务类时,通过注解将属性注册为输入或输出非常容易。为了演示,这是一个带有适当输入和输出及其注解的骨架任务实现
package org.example;
import java.util.HashMap;
import org.gradle.api.DefaultTask;
import org.gradle.api.file.ConfigurableFileCollection;
import org.gradle.api.file.DirectoryProperty;
import org.gradle.api.file.FileSystemOperations;
import org.gradle.api.provider.Property;
import org.gradle.api.tasks.*;
import javax.inject.Inject;
public abstract class ProcessTemplates extends DefaultTask {
@Input
public abstract Property<TemplateEngineType> getTemplateEngine();
@InputFiles
public abstract ConfigurableFileCollection getSourceFiles();
@Nested
public abstract TemplateData getTemplateData();
@OutputDirectory
public abstract DirectoryProperty getOutputDir();
@Inject
public abstract FileSystemOperations getFs();
@TaskAction
public void processTemplates() {
// ...
}
}package org.example;
import org.gradle.api.provider.MapProperty;
import org.gradle.api.provider.Property;
import org.gradle.api.tasks.Input;
public abstract class TemplateData {
@Input
public abstract Property<String> getName();
@Input
public abstract MapProperty<String, String> getVariables();
}gradle processTemplates的输出> gradle processTemplates > Task :processTemplates BUILD SUCCESSFUL in 0s 3 actionable tasks: 3 up-to-date
gradle processTemplates的输出(再次运行)> gradle processTemplates > Task :processTemplates UP-TO-DATE BUILD SUCCESSFUL in 0s 3 actionable tasks: 3 up-to-date
这个例子有很多值得讨论的地方,所以我们来逐一讲解每个输入和输出属性
-
templateEngine表示在处理源模板时使用哪个引擎,例如 FreeMarker、Velocity 等。您可以将其实现为字符串,但在本例中,我们选择了一个自定义枚举,因为它提供了更好的类型信息和安全性。由于枚举自动实现
Serializable,我们可以将其视为简单值并使用@Input注解,就像我们处理String属性一样。 -
sourceFiles任务将要处理的源模板。单个文件和文件集合需要它们自己的特殊注解。在本例中,我们正在处理输入文件集合,因此我们使用
@InputFiles注解。您将在稍后的表格中看到更多面向文件的注解。 -
templateData在此示例中,我们使用自定义类来表示模型数据。但是,它没有实现
Serializable,因此我们不能使用@Input注解。这不是问题,因为TemplateData中的属性(一个字符串和一个带有可序列化类型参数的哈希映射)是可序列化的,并且可以用@Input注解。我们在templateData上使用@Nested,让 Gradle 知道这是一个带有嵌套输入属性的值。 -
outputDir生成文件的目录。与输入文件一样,输出文件和目录也有几个注解。表示单个目录的属性需要
@OutputDirectory。您很快就会了解其他注解。
这些带注解的属性意味着,如果源文件、模板引擎、模型数据或生成的文件自上次 Gradle 执行任务以来没有更改,Gradle 将跳过该任务。这通常会节省大量时间。您可以稍后了解 Gradle 如何检测更改。
这个例子特别有趣,因为它处理源文件集合。如果只有一个源文件更改了会发生什么?任务会再次处理所有源文件还是只处理修改过的文件?这取决于任务的实现。如果是后者,那么任务本身就是增量的,但这与我们在此讨论的功能不同。Gradle 通过其增量任务输入功能帮助任务实现者解决这个问题。
现在您已经看到了一些实际的输入和输出注解,让我们来看看所有可用的注解以及何时应该使用它们。下表列出了可用的注解以及您可以与每个注解一起使用的相应属性类型。
| 注解 | 预期属性类型 | 描述 |
|---|---|---|
任何 |
简单的输入值或依赖解析结果 |
|
|
单个输入文件(非目录) |
|
|
单个输入目录(非文件) |
|
|
输入文件和目录的可迭代对象 |
|
|
表示 Java 类路径的输入文件和目录的可迭代对象。这允许任务忽略属性中不相关的更改,例如相同文件的不同名称。它类似于将属性注解为 注意: |
|
|
表示 Java 编译类路径的输入文件和目录的可迭代对象。这允许任务忽略不影响类路径中类 API 的不相关更改。另请参阅使用类路径注解。 将忽略以下类型的类路径更改
注意 - |
|
|
单个输出文件(非目录) |
|
|
单个输出目录(非文件) |
|
|
输出文件的可迭代对象或映射。使用文件树会关闭任务的缓存。 |
|
|
输出目录的可迭代对象。使用文件树会关闭任务的缓存。 |
|
|
指定此任务删除的一个或多个文件。请注意,任务可以定义输入/输出或可销毁项,但不能同时定义两者。 |
|
|
指定一个或多个表示任务本地状态的文件。这些文件在任务从缓存加载时被删除。 |
|
任何自定义类型 |
不实现 |
|
任何类型 |
指示该属性既不是输入也不是输出。它只是以某种方式影响任务的控制台输出,例如增加或减少任务的详细程度。 |
|
任何类型 |
指示该属性在内部使用,但既不是输入也不是输出。 |
|
任何类型 |
指示该属性已被另一个属性替换,应作为输入或输出忽略。 |
|
|
与 暗示 |
|
|
与 |
|
任何类型 |
||
|
||
|
与 |
|
|
与 |
|
与上述类似, |
注解从所有父类型(包括实现的接口)继承。属性类型注解会覆盖父类型中声明的任何其他属性类型注解。这样,@InputFile属性可以在子任务类型中转换为@InputDirectory属性。
在类型中声明的属性上的注解会覆盖超类和任何实现的接口中声明的类似注解。超类注解优先于在实现的接口中声明的注解。
表中的Console和Internal注解是特例,因为它们既不声明任务输入也不声明任务输出。那么为什么要使用它们呢?这是为了让您可以利用Java Gradle Plugin Development 插件来帮助您开发和发布自己的插件。此插件会检查您的自定义任务类的任何属性是否缺少增量构建注解。这可以保护您在开发过程中忘记添加适当的注解。
使用类路径注解
除了@InputFiles,对于与 JVM 相关的任务,Gradle 理解类路径输入的概念。在 Gradle 查找更改时,运行时和编译类路径的处理方式不同。
与用@InputFiles注解的输入属性不同,对于类路径属性,文件集合中条目的顺序很重要。另一方面,类路径本身的目录和 jar 文件的名称和路径被忽略。类路径中 jar 文件内部的类文件和资源的时间戳和顺序也被忽略,因此使用不同的文件日期重新创建 jar 文件不会使任务过时。
使用@CompileClasspath注解的输入属性被视为 Java 编译类路径。除了前面提到的通用类路径规则之外,编译类路径忽略除类文件以外的所有更改。Gradle 使用Java 编译避免中描述的相同类分析来进一步过滤不影响类 ABI 的更改。这意味着只触及类实现的更改不会使任务过时。
嵌套输入
在分析@Nested任务属性以查找声明的输入和输出子属性时,Gradle 使用实际值的类型。因此,它可以发现运行时子类型声明的所有子属性。
当将@Nested添加到可迭代对象时,每个元素都被视为单独的嵌套输入。可迭代对象中的每个嵌套输入都被分配一个名称,默认情况下是美元符号后跟可迭代对象中的索引,例如$2。如果可迭代对象的一个元素实现Named,则该名称用作属性名称。如果并非所有元素都实现Named,则可迭代对象中元素的顺序对于可靠的最新检查和缓存至关重要。不允许具有相同名称的多个元素。
当将@Nested添加到映射时,每个值都会添加一个嵌套输入,使用键作为名称。
嵌套输入的类型和类路径也受到跟踪。这确保了嵌套输入实现的更改会导致构建过时。通过这种方式,还可以将用户提供的代码作为输入添加,例如通过使用@Nested注解@Action属性。请注意,对此类操作的任何输入都应进行跟踪,无论是通过操作上的注解属性还是通过手动将其注册到任务。
使用嵌套输入可以为任务提供更丰富的建模和可扩展性,例如Test.getJvmArgumentProviders()所示。
这允许我们对 JaCoCo Java 代理进行建模,从而声明必要的 JVM 参数并向 Gradle 提供输入和输出
class JacocoAgent implements CommandLineArgumentProvider {
private final JacocoTaskExtension jacoco;
public JacocoAgent(JacocoTaskExtension jacoco) {
this.jacoco = jacoco;
}
@Nested
@Optional
public JacocoTaskExtension getJacoco() {
return jacoco.isEnabled() ? jacoco : null;
}
@Override
public Iterable<String> asArguments() {
return jacoco.isEnabled() ? ImmutableList.of(jacoco.getAsJvmArg()) : Collections.<String>emptyList();
}
}
test.getJvmArgumentProviders().add(new JacocoAgent(extension));为此,JacocoTaskExtension需要具有正确的输入和输出注解。
该方法适用于测试 JVM 参数,因为Test.getJvmArgumentProviders()是使用@Nested注解的Iterable。
还有其他任务类型提供这种嵌套输入
-
JavaExec.getArgumentProviders() - 例如自定义工具的模型
-
JavaExec.getJvmArgumentProviders() - 用于 Jacoco Java 代理
-
CompileOptions.getCompilerArgumentProviders() - 例如注解处理器的模型
-
Exec.getArgumentProviders() - 例如自定义工具的模型
-
JavaCompile.getOptions().getForkOptions().getJvmArgumentProviders() - Java 编译器守护程序命令行参数模型
-
GroovyCompile.getGroovyOptions().getForkOptions().getJvmArgumentProviders() - Groovy 编译器守护程序命令行参数模型
-
ScalaCompile.getScalaOptions().getForkOptions().getJvmArgumentProviders() - Scala 编译器守护程序命令行参数模型
同样,这种建模也可用于自定义任务。
通过运行时 API 声明输入和输出
自定义任务类是引入自己的构建逻辑到增量构建领域的一种简单方法,但您并不总是拥有该选项。这就是为什么 Gradle 还提供了一个替代 API,可以用于任何任务,我们接下来将讨论它。
当您无法访问自定义任务类的源代码时,无法添加我们在上一节中介绍的任何注解。幸运的是,Gradle 为此类场景提供了运行时 API。您将很快看到,它也可以用于临时任务。
声明临时任务的输入和输出
此运行时 API 通过每个 Gradle 任务上可用的几个命名恰当的属性提供
这些对象具有允许您指定构成任务输入和输出的文件、目录和值的方法。事实上,运行时 API 几乎与注解具有相同的功能。
它缺乏以下等效项
让我们以前面的模板处理示例为例,看看它作为使用运行时 API 的临时任务会是什么样子
tasks.register("processTemplatesAdHoc") {
inputs.property("engine", TemplateEngineType.FREEMARKER)
inputs.files(fileTree("src/templates"))
.withPropertyName("sourceFiles")
.withPathSensitivity(PathSensitivity.RELATIVE)
inputs.property("templateData.name", "docs")
inputs.property("templateData.variables", mapOf("year" to "2013"))
outputs.dir(layout.buildDirectory.dir("genOutput2"))
.withPropertyName("outputDir")
doLast {
// Process the templates here
}
}tasks.register('processTemplatesAdHoc') {
inputs.property('engine', TemplateEngineType.FREEMARKER)
inputs.files(fileTree('src/templates'))
.withPropertyName('sourceFiles')
.withPathSensitivity(PathSensitivity.RELATIVE)
inputs.property('templateData.name', 'docs')
inputs.property('templateData.variables', [year: '2013'])
outputs.dir(layout.buildDirectory.dir('genOutput2'))
.withPropertyName('outputDir')
doLast {
// Process the templates here
}
}gradle processTemplatesAdHoc的输出> gradle processTemplatesAdHoc > Task :processTemplatesAdHoc BUILD SUCCESSFUL in 0s 3 actionable tasks: 3 executed
如前所述,有很多值得讨论的地方。首先,您应该为此编写一个自定义任务类,因为它是一个具有多个配置选项的非平凡实现。在这种情况下,没有任务属性来存储根源文件夹、输出目录的位置或任何其他设置。这是故意为之,以突出运行时 API 不需要任务具有任何状态的事实。在增量构建方面,上述临时任务将与自定义任务类表现相同。
所有输入和输出定义都通过inputs和outputs上的方法完成,例如property()、files()和dir()。Gradle 对参数值执行最新检查,以确定任务是否需要再次运行。每个方法都对应一个增量构建注解,例如inputs.property()映射到@Input,outputs.dir()映射到@OutputDirectory。
任务删除的文件可以通过destroyables.register()指定。
tasks.register("removeTempDir") {
val tmpDir = layout.projectDirectory.dir("tmpDir")
destroyables.register(tmpDir)
doLast {
tmpDir.asFile.deleteRecursively()
}
}tasks.register('removeTempDir') {
def tempDir = layout.projectDirectory.dir('tmpDir')
destroyables.register(tempDir)
doLast {
tempDir.asFile.deleteDir()
}
}运行时 API 和注解之间的一个显著区别是缺少直接对应于@Nested的方法。这就是为什么示例对模板数据使用两个property()声明,每个TemplateData属性一个。在使用运行时 API 处理嵌套值时,您应该使用相同的技术。任何给定的任务都可以声明可销毁项或输入/输出,但不能同时声明两者。
细粒度配置
运行时 API 方法只允许您声明输入和输出本身。但是,面向文件的方法会返回一个构建器(类型为TaskInputFilePropertyBuilder),允许您提供有关这些输入和输出的额外信息。
您可以在其 API 文档中了解构建器提供的所有选项,但我们在此处展示一个简单示例,让您了解可以做什么。
假设我们不想在没有源文件的情况下运行processTemplates任务,无论它是否是干净构建。毕竟,如果没有源文件,任务就没什么可做的。构建器允许我们这样配置:
tasks.register("processTemplatesAdHocSkipWhenEmpty") {
// ...
inputs.files(fileTree("src/templates") {
include("**/*.fm")
})
.skipWhenEmpty()
.withPropertyName("sourceFiles")
.withPathSensitivity(PathSensitivity.RELATIVE)
.ignoreEmptyDirectories()
// ...
}tasks.register('processTemplatesAdHocSkipWhenEmpty') {
// ...
inputs.files(fileTree('src/templates') {
include '**/*.fm'
})
.skipWhenEmpty()
.withPropertyName('sourceFiles')
.withPathSensitivity(PathSensitivity.RELATIVE)
.ignoreEmptyDirectories()
// ...
}gradle clean processTemplatesAdHocSkipWhenEmpty的输出> gradle clean processTemplatesAdHocSkipWhenEmpty > Task :processTemplatesAdHocSkipWhenEmpty NO-SOURCE BUILD SUCCESSFUL in 0s 3 actionable tasks: 2 executed, 1 up-to-date
TaskInputs.files()方法返回一个具有skipWhenEmpty()方法的构建器。调用此方法等同于使用@SkipWhenEmpty注解该属性。
现在您已经看到了注解和运行时 API,您可能会想应该使用哪个 API。我们的建议是尽可能使用注解,有时为了使用它们,甚至值得创建一个自定义任务类。运行时 API 更多用于您无法使用注解的情况。
声明自定义任务类型的输入和输出
另一种示例类型涉及为自定义任务类的实例注册额外的输入和输出。例如,假设ProcessTemplates任务还需要读取src/headers/headers.txt(例如,因为它包含在某个源中)。您希望 Gradle 知道此输入文件,以便在文件内容更改时重新执行任务。使用运行时 API 就可以做到这一点
tasks.register<ProcessTemplates>("processTemplatesWithExtraInputs") {
// ...
inputs.file("src/headers/headers.txt")
.withPropertyName("headers")
.withPathSensitivity(PathSensitivity.NONE)
}tasks.register('processTemplatesWithExtraInputs', ProcessTemplates) {
// ...
inputs.file('src/headers/headers.txt')
.withPropertyName('headers')
.withPathSensitivity(PathSensitivity.NONE)
}像这样使用运行时 API 有点像使用doLast()和doFirst()将额外操作附加到任务,只不过在这种情况下,我们附加的是有关输入和输出的信息。
| 如果任务类型已经在使用增量构建注解,则使用相同属性名称注册输入或输出将导致错误。 |
声明任务输入和输出的好处
一旦你声明了任务的正式输入和输出,Gradle 就可以推断出这些属性。例如,如果一个任务的输入被设置为另一个任务的输出,那意味着第一个任务依赖于第二个任务,对吗?Gradle 知道这一点并可以据此采取行动。
接下来我们将探讨此功能以及其他一些来自 Gradle 了解输入和输出的功能。
推断的任务依赖关系
考虑一个归档任务,它打包processTemplates任务的输出。构建作者会发现归档任务显然需要processTemplates首先运行,因此可能会添加显式的dependsOn。但是,如果您这样定义归档任务:
tasks.register<Zip>("packageFiles") {
from(processTemplates.map { it.outputDir })
}tasks.register('packageFiles', Zip) {
from processTemplates.map { it.outputDir }
}gradle clean packageFiles的输出> gradle clean packageFiles > Task :processTemplates > Task :packageFiles BUILD SUCCESSFUL in 0s 5 actionable tasks: 4 executed, 1 up-to-date
Gradle 将自动使packageFiles依赖于processTemplates。它之所以能做到这一点,是因为它知道packageFiles的其中一个输入需要processTemplates任务的输出。我们称之为推断的任务依赖关系。
以上示例也可以这样写
tasks.register<Zip>("packageFiles2") {
from(processTemplates)
}tasks.register('packageFiles2', Zip) {
from processTemplates
}gradle clean packageFiles2的输出> gradle clean packageFiles2 > Task :processTemplates > Task :packageFiles2 BUILD SUCCESSFUL in 0s 5 actionable tasks: 4 executed, 1 up-to-date
这是因为from()方法可以接受任务对象作为参数。在幕后,from()使用project.files()方法包装参数,这反过来又将任务的正式输出公开为文件集合。换句话说,这是一个特例!
输入和输出验证
增量构建注解提供了足够的信息,让 Gradle 对注解属性执行一些基本验证。特别是,它在任务执行之前为每个属性执行以下操作:
-
@InputFile- 验证属性是否有值,并且路径对应于存在的文件(而非目录)。 -
@InputDirectory- 与@InputFile相同,只是路径必须对应于目录。 -
@OutputDirectory- 验证路径不与文件匹配,如果目录不存在,则创建它。
如果一个任务在某个位置产生输出,而另一个任务通过将该位置引用为输入来使用该位置,则 Gradle 会检查消费者任务是否依赖于生产者任务。当生产者和消费者任务同时执行时,构建会失败以避免捕获不正确的状态。
这种验证提高了构建的健壮性,使您能够快速识别与输入和输出相关的问题。
您偶尔会想禁用一些此类验证,特别是在输入文件可能合法地不存在时。这就是 Gradle 提供@Optional注解的原因:您可以使用它来告诉 Gradle 某个特定输入是可选的,因此如果相应的文件或目录不存在,构建不应失败。
持续构建
定义任务输入和输出的另一个好处是持续构建。由于 Gradle 知道任务依赖于哪些文件,因此如果任何输入发生更改,它会自动再次运行任务。通过在运行 Gradle 时激活持续构建(通过--continuous或-t选项),您将使 Gradle 进入一种状态,即它会持续检查更改并在遇到此类更改时执行请求的任务。
您可以在持续构建中找到有关此功能的更多信息。
任务并行性
定义任务输入和输出的最后一个好处是 Gradle 可以利用这些信息来决定在使用“--parallel”选项时如何运行任务。例如,Gradle 会在选择要运行的下一个任务时检查任务的输出,并避免同时执行写入相同输出目录的任务。同样,Gradle 会使用有关任务销毁哪些文件(例如,通过Destroys注解指定)的信息,并避免在另一个任务正在运行并消耗或创建这些相同文件时运行删除一组文件的任务(反之亦然)。它还可以确定创建一组文件的任务已经运行,而消耗这些文件的任务尚未运行,并避免在此期间运行删除这些文件的任务。通过这种方式提供任务输入和输出信息,Gradle 可以推断任务之间的创建/消耗/销毁关系,并确保任务执行不会违反这些关系。
工作原理
在任务首次执行之前,Gradle 会对输入进行指纹识别。此指纹包含输入文件的路径和每个文件内容的哈希值。然后 Gradle 执行任务。如果任务成功完成,Gradle 会对输出进行指纹识别。此指纹包含输出文件集和每个文件内容的哈希值。Gradle 会将这两个指纹保留到任务下次执行时使用。
此后每次,在任务执行之前,Gradle 都会对输入和输出进行新的指纹识别。如果新指纹与以前的指纹相同,Gradle 则认为输出是最新的并跳过任务。如果不同,Gradle 则执行任务。Gradle 会将这两个指纹保留到任务下次执行时使用。
如果文件的统计信息(即lastModified和size)没有更改,Gradle 将重用上次运行的文件指纹。这意味着当文件的统计信息没有更改时,Gradle 不会检测到更改。
Gradle 还将任务的代码视为任务输入的一部分。当任务、其操作或其依赖项在执行之间发生更改时,Gradle 会将任务视为过时的。
Gradle 了解文件属性(例如,持有 Java 类路径的文件属性)是否对顺序敏感。在比较此类属性的指纹时,即使文件顺序的更改也会导致任务过时。
请注意,如果任务指定了输出目录,则自上次执行以来添加到该目录的任何文件都将被忽略,并且不会导致任务过时。这是为了让不相关的任务可以共享一个输出目录而不会相互干扰。如果出于某种原因这不是您想要的行为,请考虑使用TaskOutputs.upToDateWhen(groovy.lang.Closure)
另请注意,更改不可用文件的可用性(例如,将损坏的符号链接的目标修改为有效文件,反之亦然)将由最新检查检测和处理。
为了跟踪任务、任务操作和嵌套输入的实现,Gradle 使用类名和包含实现的类路径的标识符。在某些情况下,Gradle 无法精确跟踪实现
- 未知类加载器
-
当加载实现的类加载器不是由 Gradle 创建时,无法确定类路径。
- Java lambda
-
Java lambda 类在运行时创建,具有非确定性类名。因此,类名无法标识 lambda 的实现,并且在不同的 Gradle 运行之间会发生变化。
当任务、任务操作或嵌套输入的实现无法精确跟踪时,Gradle 会禁用任务的任何缓存。这意味着任务将永远不会是最新的或从构建缓存中加载。
高级技巧
您到目前为止在本节中看到的所有内容将涵盖您遇到的大多数用例,但有些场景需要特殊处理。接下来我们将介绍其中的几个以及相应的解决方案。
添加您自己的缓存输入/输出方法
您有没有想过Copy任务的from()方法是如何工作的?它没有用@InputFiles注解,但传递给它的任何文件都被视为任务的正式输入。发生了什么?
实现很简单,您可以使用相同的技术来改进您自己任务的 API。编写您的方法,使其将文件直接添加到适当的带注解属性中。例如,以下是如何向我们之前介绍的自定义ProcessTemplates类添加sources()方法:
tasks.register<ProcessTemplates>("processTemplates") {
templateEngine = TemplateEngineType.FREEMARKER
templateData.name = "test"
templateData.variables = mapOf("year" to "2012")
outputDir = layout.buildDirectory.dir("genOutput")
sources(fileTree("src/templates"))
}tasks.register('processTemplates', ProcessTemplates) {
templateEngine = TemplateEngineType.FREEMARKER
templateData.name = 'test'
templateData.variables = [year: '2012']
outputDir = file(layout.buildDirectory.dir('genOutput'))
sources fileTree('src/templates')
}public abstract class ProcessTemplates extends DefaultTask {
// ...
@SkipWhenEmpty
@InputFiles
@PathSensitive(PathSensitivity.NONE)
public abstract ConfigurableFileCollection getSourceFiles();
public void sources(FileCollection sourceFiles) {
getSourceFiles().from(sourceFiles);
}
// ...
}gradle processTemplates的输出> gradle processTemplates > Task :processTemplates BUILD SUCCESSFUL in 0s 3 actionable tasks: 3 executed
换句话说,只要您在配置阶段将值和文件添加到正式的任务输入和输出中,无论您从构建中的何处添加它们,它们都将被视为如此。
如果我们还想支持将任务作为参数,并将其输出视为输入,我们可以直接使用TaskProvider,如下所示:
val copyTemplates by tasks.registering(Copy::class) {
into(file(layout.buildDirectory.dir("tmp")))
from("src/templates")
}
tasks.register<ProcessTemplates>("processTemplates2") {
// ...
sources(copyTemplates)
}def copyTemplates = tasks.register('copyTemplates', Copy) {
into file(layout.buildDirectory.dir('tmp'))
from 'src/templates'
}
tasks.register('processTemplates2', ProcessTemplates) {
// ...
sources copyTemplates
} // ...
public void sources(TaskProvider<?> inputTask) {
getSourceFiles().from(inputTask);
}
// ...gradle processTemplates2的输出> gradle processTemplates2 > Task :copyTemplates > Task :processTemplates2 BUILD SUCCESSFUL in 0s 4 actionable tasks: 4 executed
此技术可以使您的自定义任务更易于使用,并使构建文件更清晰。作为额外的好处,我们使用TaskProvider意味着我们的自定义方法可以设置推断的任务依赖关系。
最后一点:如果您正在开发一个将源文件集合作为输入的任务,就像这个示例一样,请考虑使用内置的SourceTask。它将为您省去实现我们放入ProcessTemplates中的一些管道工作。
将 @OutputDirectory 链接到 @InputFiles
当您希望将一个任务的输出链接到另一个任务的输入时,类型通常匹配,简单的属性赋值将提供该链接。例如,可以将File输出属性赋值给File输入。
不幸的是,当您希望任务的@OutputDirectory中的文件(类型为File)成为另一个任务的@InputFiles属性(类型为FileCollection)的来源时,这种方法就失效了。由于两者具有不同的类型,属性赋值将不起作用。
例如,假设您想使用 Java 编译任务的输出(通过destinationDir属性)作为自定义任务的输入,该任务对一组包含 Java 字节码的文件进行插桩。此自定义任务,我们称之为Instrument,具有一个用@InputFiles注解的classFiles属性。您最初可能尝试这样配置任务:
plugins {
id("java-library")
}
tasks.register<Instrument>("badInstrumentClasses") {
classFiles.from(fileTree(tasks.compileJava.flatMap { it.destinationDirectory }))
destinationDir = layout.buildDirectory.dir("instrumented")
}plugins {
id 'java-library'
}
tasks.register('badInstrumentClasses', Instrument) {
classFiles.from fileTree(tasks.named('compileJava').flatMap { it.destinationDirectory }) {}
destinationDir = file(layout.buildDirectory.dir('instrumented'))
}gradle clean badInstrumentClasses的输出> gradle clean badInstrumentClasses > Task :clean UP-TO-DATE > Task :badInstrumentClasses NO-SOURCE BUILD SUCCESSFUL in 0s 3 actionable tasks: 2 executed, 1 up-to-date
这段代码没有明显的错误,但从控制台输出可以看出缺少编译任务。在这种情况下,您需要通过dependsOn在instrumentClasses和compileJava之间添加显式任务依赖关系。使用fileTree()意味着 Gradle 无法自行推断任务依赖关系。
一种解决方案是使用TaskOutputs.files属性,如下例所示:
tasks.register<Instrument>("instrumentClasses") {
classFiles.from(tasks.compileJava.map { it.outputs.files })
destinationDir = layout.buildDirectory.dir("instrumented")
}tasks.register('instrumentClasses', Instrument) {
classFiles.from tasks.named('compileJava').map { it.outputs.files }
destinationDir = file(layout.buildDirectory.dir('instrumented'))
}gradle clean instrumentClasses的输出> gradle clean instrumentClasses > Task :clean UP-TO-DATE > Task :compileJava > Task :instrumentClasses BUILD SUCCESSFUL in 0s 5 actionable tasks: 4 executed, 1 up-to-date
或者,您可以使用project.files()、project.layout.files()或project.objects.fileCollection()代替project.fileTree()来让 Gradle 访问相应的属性:
layout.files()设置推断任务依赖关系tasks.register<Instrument>("instrumentClasses2") {
classFiles.from(layout.files(tasks.compileJava))
destinationDir = layout.buildDirectory.dir("instrumented")
}tasks.register('instrumentClasses2', Instrument) {
classFiles.from layout.files(tasks.named('compileJava'))
destinationDir = file(layout.buildDirectory.dir('instrumented'))
}gradle clean instrumentClasses2的输出> gradle clean instrumentClasses2 > Task :clean UP-TO-DATE > Task :compileJava > Task :instrumentClasses2 BUILD SUCCESSFUL in 0s 5 actionable tasks: 4 executed, 1 up-to-date
请记住,files()、layout.files()和objects.fileCollection()可以接受任务作为参数,而fileTree()不能。
这种方法的缺点是源任务的所有文件输出都成为目标的输入文件——本例中是instrumentClasses。只要源任务只有一个基于文件的输出,例如JavaCompile任务,这就可以了。但是,如果您必须在多个输出属性中只链接一个输出属性,那么您需要使用builtBy方法明确告诉 Gradle 哪个任务生成输入文件
tasks.register<Instrument>("instrumentClassesBuiltBy") {
classFiles.from(fileTree(tasks.compileJava.flatMap { it.destinationDirectory }) {
builtBy(tasks.compileJava)
})
destinationDir = layout.buildDirectory.dir("instrumented")
}tasks.register('instrumentClassesBuiltBy', Instrument) {
classFiles.from fileTree(tasks.named('compileJava').flatMap { it.destinationDirectory }) {
builtBy tasks.named('compileJava')
}
destinationDir = file(layout.buildDirectory.dir('instrumented'))
}gradle clean instrumentClassesBuiltBy的输出> gradle clean instrumentClassesBuiltBy > Task :clean UP-TO-DATE > Task :compileJava > Task :instrumentClassesBuiltBy BUILD SUCCESSFUL in 0s 5 actionable tasks: 4 executed, 1 up-to-date
您当然也可以通过dependsOn添加显式任务依赖,但上述方法提供了更多的语义含义,解释了为什么compileJava必须提前运行。
禁用最新检查
Gradle 自动处理输出文件和目录的最新检查,但如果任务输出完全是其他东西怎么办?也许它是一个 Web 服务或数据库表的更新。或者有时您有一个应该始终运行的任务。
这就是Task上的doNotTrackState()方法的作用。可以使用它完全禁用任务的最新检查,如下所示:
tasks.register<Instrument>("alwaysInstrumentClasses") {
classFiles.from(layout.files(tasks.compileJava))
destinationDir = layout.buildDirectory.dir("instrumented")
doNotTrackState("Instrumentation needs to re-run every time")
}tasks.register('alwaysInstrumentClasses', Instrument) {
classFiles.from layout.files(tasks.named('compileJava'))
destinationDir = file(layout.buildDirectory.dir('instrumented'))
doNotTrackState("Instrumentation needs to re-run every time")
}gradle clean alwaysInstrumentClasses的输出> gradle clean alwaysInstrumentClasses > Task :compileJava > Task :alwaysInstrumentClasses BUILD SUCCESSFUL in 0s 4 actionable tasks: 1 executed, 3 up-to-date
gradle alwaysInstrumentClasses的输出> gradle alwaysInstrumentClasses > Task :compileJava UP-TO-DATE > Task :alwaysInstrumentClasses BUILD SUCCESSFUL in 0s 4 actionable tasks: 1 executed, 3 up-to-date
如果您正在编写一个始终应该运行的自定义任务,那么您也可以在任务类上使用@UntrackedTask注解,而不是调用Task.doNotTrackState()。
集成自己的最新检查的外部工具
有时您希望集成像 Git 或 Npm 这样的外部工具,它们都有自己的最新检查功能。在这种情况下,Gradle 再进行最新检查就没有多大意义了。您可以通过在封装工具的任务上使用@UntrackedTask注解来禁用 Gradle 的最新检查。或者,您可以使用运行时 API 方法Task.doNotTrackState()。
例如,假设您想实现一个克隆 Git 仓库的任务。
@UntrackedTask(because = "Git tracks the state") (1)
public abstract class GitClone extends DefaultTask {
@Input
public abstract Property<String> getRemoteUri();
@Input
public abstract Property<String> getCommitId();
@OutputDirectory
public abstract DirectoryProperty getDestinationDir();
@TaskAction
public void gitClone() throws IOException {
File destinationDir = getDestinationDir().get().getAsFile().getAbsoluteFile(); (2)
String remoteUri = getRemoteUri().get();
// Fetch origin or clone and checkout
// ...
}
}tasks.register<GitClone>("cloneGradleProfiler") {
destinationDir = layout.buildDirectory.dir("gradle-profiler") // <3
remoteUri = "https://github.com/gradle/gradle-profiler.git"
commitId = "d6c18a21ca6c45fd8a9db321de4478948bdf801b"
}tasks.register("cloneGradleProfiler", GitClone) {
destinationDir = layout.buildDirectory.dir("gradle-profiler") (3)
remoteUri = "https://github.com/gradle/gradle-profiler.git"
commitId = "d6c18a21ca6c45fd8a9db321de4478948bdf801b"
}| 1 | 将任务声明为未跟踪。 |
| 2 | 使用输出目录来运行外部工具。 |
| 3 | 在您的构建中添加任务并配置输出目录。 |
配置输入规范化
为了进行最新检查和构建缓存,Gradle 需要确定两个任务输入属性是否具有相同的值。为此,Gradle 首先对两个输入进行规范化,然后比较结果。例如,对于编译类路径,Gradle 从类路径上的类中提取 ABI 签名,然后比较上次 Gradle 运行和当前 Gradle 运行之间的签名,如Java 编译避免中所述。
规范化适用于类路径上的所有 zip 文件(例如 jar、war、aar、apk 等)。这使得 Gradle 能够识别两个 zip 文件在功能上是否相同,即使 zip 文件本身由于元数据(例如时间戳或文件顺序)而略有不同。规范化不仅适用于类路径上直接的 zip 文件,还适用于目录内部或类路径上其他 zip 文件内部嵌套的 zip 文件。
可以自定义 Gradle 内置的运行时类路径规范化策略。所有用@Classpath注解的输入都被视为运行时类路径。
假设您想在所有生成的 jar 文件中添加一个build-info.properties文件,其中包含有关构建的信息,例如构建开始的时间戳或用于识别发布 artifact 的 CI 作业 ID。此文件仅用于审计目的,对运行测试的结果没有影响。尽管如此,此文件是test任务运行时类路径的一部分,并且在每次构建调用时都会更改。因此,test将永远不会是最新的或从构建缓存中拉取。为了再次受益于增量构建,您可以在项目级别告诉 Gradle 忽略运行时类路径上的此文件,方法是使用Project.normalization(org.gradle.api.Action)(在使用项目中)
normalization {
runtimeClasspath {
ignore("build-info.properties")
}
}normalization {
runtimeClasspath {
ignore 'build-info.properties'
}
}如果将此类文件添加到 jar 文件是您所有项目中都会做的事情,并且您想为所有消费者过滤此文件,则应考虑在约定插件中配置此类规范化,以便在子项目之间共享。
此配置的效果是,对build-info.properties的更改将被忽略,用于最新检查和构建缓存键计算。请注意,这不会更改test任务的运行时行为——即,任何测试仍然能够加载build-info.properties,并且运行时类路径仍然与以前相同。
属性文件规范化
默认情况下,属性文件(即以.properties扩展名结尾的文件)将被规范化,以忽略注释、空白和属性顺序的差异。Gradle 通过加载属性文件并在最新检查或构建缓存键计算期间仅考虑单个属性来实现这一点。
然而,有时某些属性具有运行时影响,而另一些则没有。如果某个属性发生变化,但对运行时类路径没有影响,则可能需要将其从最新检查和构建缓存键计算中排除。但是,排除整个文件也会排除具有运行时影响的属性。在这种情况下,可以有选择地从运行时类路径上的任何或所有属性文件中排除属性。
可以使用RuntimeClasspathNormalization中描述的模式将忽略属性的规则应用于特定的文件集。如果文件与规则匹配,但无法作为属性文件加载(例如,因为它格式不正确或使用非标准编码),它将被作为普通文件合并到最新或构建缓存键计算中。换句话说,如果文件无法作为属性文件加载,则对空白、属性顺序或注释的任何更改都可能导致任务过时或导致缓存未命中。
normalization {
runtimeClasspath {
properties("**/build-info.properties") {
ignoreProperty("timestamp")
}
}
}normalization {
runtimeClasspath {
properties('**/build-info.properties') {
ignoreProperty 'timestamp'
}
}
}normalization {
runtimeClasspath {
properties {
ignoreProperty("timestamp")
}
}
}normalization {
runtimeClasspath {
properties {
ignoreProperty 'timestamp'
}
}
}Java META-INF 规范化
对于 jar 归档中META-INF目录中的文件,由于它们的运行时影响,并非总是能够完全忽略文件。
META-INF中的清单文件被规范化以忽略注释、空白和顺序差异。清单属性名称不区分大小写和顺序进行比较。清单属性文件根据属性文件规范化进行规范化。
META-INF清单属性normalization {
runtimeClasspath {
metaInf {
ignoreAttribute("Implementation-Version")
}
}
}normalization {
runtimeClasspath {
metaInf {
ignoreAttribute("Implementation-Version")
}
}
}META-INF属性键normalization {
runtimeClasspath {
metaInf {
ignoreProperty("app.version")
}
}
}normalization {
runtimeClasspath {
metaInf {
ignoreProperty("app.version")
}
}
}META-INF/MANIFEST.MFnormalization {
runtimeClasspath {
metaInf {
ignoreManifest()
}
}
}normalization {
runtimeClasspath {
metaInf {
ignoreManifest()
}
}
}META-INF中所有文件和目录normalization {
runtimeClasspath {
metaInf {
ignoreCompletely()
}
}
}normalization {
runtimeClasspath {
metaInf {
ignoreCompletely()
}
}
}提供自定义最新逻辑
Gradle 自动处理输出文件和目录的最新检查,但如果任务输出完全是其他东西怎么办?也许它是一个 Web 服务或数据库表的更新。在这种情况下,Gradle 无法知道如何检查任务是否最新。
这就是TaskOutputs上的upToDateWhen()方法的作用。这会接受一个谓词函数,用于确定任务是否最新。例如,您可以从数据库中读取数据库模式的版本号。或者,您可以检查数据库表中是否存在特定记录或是否已更改。
请注意,最新检查应该节省您的时间。不要添加花费与任务标准执行时间相同或更多时间的检查。实际上,如果一个任务无论如何都经常运行,因为它很少最新,那么完全不进行最新检查可能不值得,如禁用最新检查中所述。请记住,如果任务在执行任务图中,您的检查将始终运行。
一个常见的错误是使用upToDateWhen()而不是Task.onlyIf()。如果您想根据与任务输入和输出无关的条件跳过任务,那么您应该使用onlyIf()。例如,在您希望在某个特定属性已设置或未设置时跳过任务的情况下。
过时的任务输出
当 Gradle 版本更改时,Gradle 会检测到需要删除使用旧版本 Gradle 运行的任务的输出,以确保最新版本的任务从已知干净状态开始。
| 过时输出目录的自动清理仅针对源集(Java/Groovy/Scala 编译)的输出实现。 |